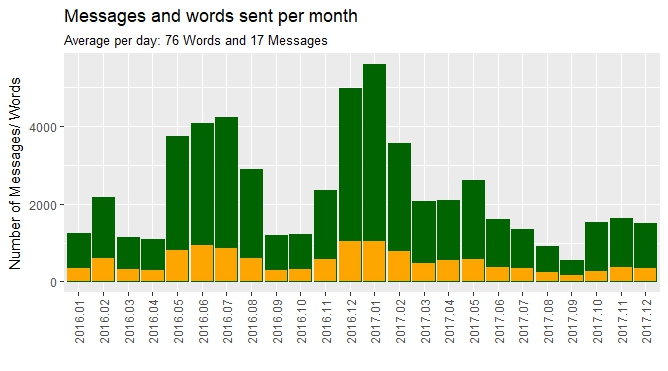
I recently saw some people on Reddit analyzing their chat-conversations and I wanted to try it too. You can export a Whatsapp-Conversation by sending it as an Email to yourself. You will receive a txt-File with all the conversations. Because it isn’t formatted in a useful manner, you have to do it yourself. I will do this in this post and analyse the data in a second one. So this will be a bit more technical than usual. You can find the complete code here.
I used the readLines-Command and encode it in UFT-8 because the language is German and there are letters like ö,ä and ü.
whatsapp = readLines('whatsapp analyse/whatsapp.txt',encoding="UTF-8")
The format of the lines isn’t too bad, there is a clear structure. It looks like this:
08.04.15, 00:09 – Adrian: Bye
08.04.15, 00:09 – Bartholomäus: brb
The problem is there are lines some lines which are just text. That happens if the written messages are long. To check every single line I created a loop and checked if it an extra-line. If not I put the different categories (date, time, author, message) each into a matrix. I create two name variables, to account for the different length of the names.
nameA="Adrian"
nameB="Bartholomäus"
extralines=c()
sorted=matrix(nrow = length(whatsapp), ncol = 4)
for(i in 1:length(whatsapp)) {
#If Dates aren't in this format: '08.04.15, 00:09' - Substring-numbers need to be changed.
#The condition checks for the dot and the comma
if(substring(whatsapp[i],9,10)==", "& substring(whatsapp[i],3,3)=="."){
#fill date, time collumn
sorted[i,1]=substr(whatsapp[i],0,8)
sorted[i,2]=substr(whatsapp[i],11,15)
#different length of names. just checks for the first two letters
if(substr(whatsapp[i],19,20)==substr(nameA,1,2)){
sorted[i,3]=nameA
#Adds everything after the Name to the Message colum
sorted[i,4]=substring(whatsapp[i],19+nchar(nameA)+1)
}
else{
sorted[i,3]=nameB
#Adds everything after the Name to the Message colum
sorted[i,4]=substring(whatsapp[i],19+nchar(nameB)+1)
}
}
# save them to "extralines" and add the content to the messagefield of the line before
else{
extralines=c(extralines,i)
sorted[i-1,4]=paste(sorted[i-1,4],whatsapp[i],sep=" ")
}
}
There are probably a lot of ways to improve this and make the script more flexible. This wouldn’t work for group-conversations.
As a final step I removed the extra-lines and saved it as a data-frame. Now the analysis can start.
data=data.frame(sorted=sorted[-extralines,])
colnames(data)=c("Date","Time","Author","Message")
write.csv2(data,file="wazapdata.csv",fileEncoding = "UTF-8")
For the analysis I’ll create a separate post. If you want to see a different approach to the same problem, you can find it here. (I unfortunately found it only after finishing my script, so it’s quite different)